

Meta robots tags are something that you’re almost inevitably going to come across if you work in SEO, but what are they, how do they work and how do they differ from the good old robots.txt? Let’s find out.
What Is A Meta Robots Tag?
A meta robots tag is a snippet of code that’s placed in the header of your web page that tells search engines and other crawlers what they should do with the page. Should they crawl it and add it to their index? Should they follow links on the page? Should they display your snippet in search results in a certain way? You can control all of these with meta robots tags and, while there may be a bit more development resource required in certain content management systems, they’re generally more effective than robots.txt in a lot of regards. I’ll talk more about that later.
Typically speaking, a robots tag would look like this in your HTML source.
![]()
As you can see, it’s comprised of two elements: the naming of the meta tag (robots, in this case – meta tags have to declare their identity to work) and the directives invoked (the “content" – in this case, “noindex, follow").
This is probably the most common meta robots tag that you’ll come across and use; the meta robots noindex tag tells search engines that, while they can crawl the page, the noindex directive tells them that they should not add the page to their index. The other directive in the tag, the “follow" tells search engines that they should follow the links on the page. This is useful to know because even if the page isn’t in the search engine index, it won’t be a black hole with the flow of your site’s authority – any authority which the page has to pass to others, either on your site or off, will still be passed by using the “follow" directive.
If you wanted to completely void that page and not have any links on there followed, the tag would look like one of the following:
![]()
By adding the “nofollow" attribute, you are telling search engines to not index the page, but also not to follow any links on that page, internal or external. The “none" directive is effectively the same as combining noindex and nofollow, but it’s not as commonly used. In general, we recommend “noindex,follow" if you need to noindex a page.
What Other Meta Robots Tags Are There?
Now we’ve covered the anatomy of the most common meta robots tag, let’s take a look at some of the others:
- noimageindex: Tells the visiting crawler not to index any of the images on the page. Handy if you’ve got some proprietary images that you don’t want people finding on Google. Bear in mind that if someone links to an image, it can still be indexed.
- noarchive: This tag tells search engines not to show a cached version of the page.
- nosnippet: I genuinely can’t think of a viable use case for this one, but it stops search engines showing a snippet in the search results and stops them caching the page. If you can think of a reason to use this, ping me on Twitter @ben_johnston80.
- noodp: This tag was used to stop search engines using your DMOZ directory listing instead of your meta title/ description in search results. However, since DMOZ shut down last year, this tag has been depreciated. You might still see it in the wild, and there are some SEO plugins out there that still incorporate it for some reason, but just know that since the death of DMOZ, this tag does nothing.
- noydir: Another one that isn’t really of any use, but you’re likely to see in the wild and some SEO plugins push through – the noydir tag tells search engines not to show the snippet from the Yahoo! Directory. No search engines other than Yahoo! Use the Yahoo! Directory, and I’m not sure anyone has actually added their site to it since 2009, so it’s a genuinely useless tag.
When Should You Use Meta Robots Tags?
There are a number of reasons to use the meta tags over robots.txt, but the main one is the opportunity to deploy them on a page-by-page basis and have them followed. They are typically more effective than robots.txt and robots.txt works best when it’s used on a by-folder basis rather than a by-URL basis.
Essentially, if you need to exclude a specific page from the index, but want the links on that page to still be followed, or you have some images that you don’t want indexed but you still want the page’s content indexed, this is when you would use a meta robots tag. It’s an excellent, dynamic way of managing your site’s indexation (and there are loads of other things that you can do with them, but that’s another post).
But here’s the challenge: it’s really easy to add another line to your robots.txt file, but with some content management systems, it’s not that easy to add a meta tag to a specific page. Don’t worry, Google Tag Manager has you covered.
Adding Meta Robots Tags Through Google Tag Manager
If you have Google Tag Manager installed on your site to handle your tracking (and, seriously, why wouldn’t you?), you can use it to inject your meta robots tags on a page by page basis, thus eliminating the development overhead. Here’s how.
Firstly, create a new Custom HTML tag, incorporating the following code:
![]()
Replace YOURDIRECTIVE1, YOURDIRECTIVE2 with what you want it to do (noindex, follow, for example) and if you want to remove one of the directives, that’s fine. The screenshot below will show you how to do this.
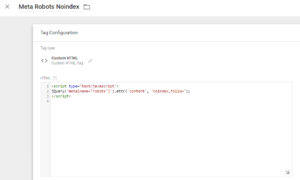
Now create a trigger and set it to only fire on the pages you want the meta robots tag to apply to, as seen below.
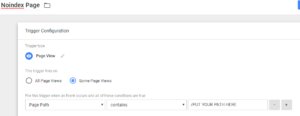
And there you go, that’s how you can inject your meta robots tags through Google Tag Manager. Pretty handy, right?
And We’re Done
Hopefully today’s post has given you a better understanding of what meta robots tags are, what you’d use them for and how to use them. Any questions or comments, drop me a Tweet or send us a message through our contact form.